
This blog explain how to scrape web data using wso2 data services web harvesting feature. In this tutorial I am going to extract Top rated books from Top Rated Books - Book Movement web page along with their authors and expose those data as a data service.
Before I begin lets look at how scraping works.
When you scrape a web page you need to identify the html/xml pattern. If we look at Top Rated Books - Book Movement page you can see list of books are listed along with their details. Now if we look at the page source we can see several html tags are repeated in the same manner.
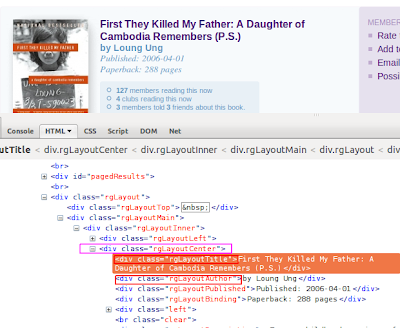
If you look at it closely you can see a wrapper element which is
<div class=”rgLayoutCenter”>
and inside that wrapper element you have some thing like this.
<div class="rgLayoutTitle">First They Killed My Father: A Daughter of Cambodia Remembers (P.S.)</div><div class="rgLayoutAuthor">by Loung Ung</div>
Now our basic requirement is to extract all the books along with their authors. To do that we need to find the pattern of the book title as wel as the author.
<div class="rgLayoutTitle">First They Killed My Father: A Daughter of Cambodia Remembers (P.S.)</div><div class="rgLayoutAuthor">by Loung Ung</div>
we can easily write an xslt template to extract these information
<?xml version="1.0" encoding="ISO-8859-1"?>
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:output method="xml" omit-xml-declaration="yes" indent="yes"/>
<xsl:template match="/">
<BookInfo>
<xsl:for-each select="//div[@class='rgLayoutCenter']">
<Book>
<Title><xsl:value-of select="div[@class='rgLayoutTitle']"/></Title>
<Author><xsl:value-of select="div[@class='rgLayoutAuthor']"/></Author>
</Book>
</xsl:for-each>
</BookInfo>
</xsl:template>
</xsl:stylesheet>
Above xslt template describe to go inside each
<div class=”rgLayoutCenter”>element and extract value of
<div class="rgLayoutTitle">and
<div class="rgLayoutAuthor">and assign it to the XML elements Title and Author inside the wrapper Book element.
Creating the web harvest data service
Now we learnt the basic concepts on web scraping/web harvesting, we will straight away create the data services using WSO2 Data services server.
To install WSO2 data services download and unzip the zip file and go to $DS_HOME/bin and start up the server from the command prompt, run bin/wso2server.bat{sh}
When the server startup is complete, access http://localhost:9443/carbon in your browser. Sign in to the server using the default credentials (username=admin, password=admin) in the right hand side corner. It will redirect you to the management console page.
To create the data service click on create in the left hand side menu under Web Services -> Add -> Create
Once you click on it you will have to fill the data service information as shown below. Lets name our data service as WebHarvestDS.
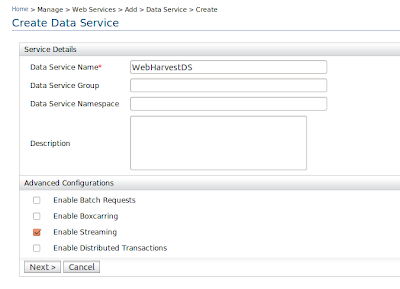
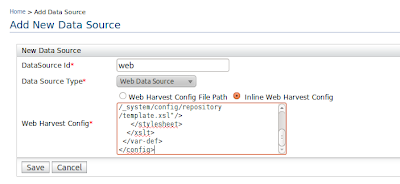
Once you click on next you will be redirected to create data-source page click on add new datasource to add our web datasource.
For the web datasource you need to have a configuration file along with the web scraping url, the scraperVariable and the HTTP method to extract data.
Also we need to provide our template.xslt file location we wrote earlier.
<?xml version="1.0" encoding="UTF-8"?><config>
<var-def name='bookInfo'>
<xslt>
<xml>
<html-to-xml>
<http method='get' url='http://www.bookmovement.com/app/readingguide/memberRecommendations.php'/>
</html-to-xml>
</xml>
<stylesheet>
<file path="/media/ntfs/web/template.xsl"/>
</stylesheet>
</xslt>
</var-def>
</config>
Place the above configuration file inside the inline configuration section (or you can save the above configuration in your local machine and give it as a web harvest config file path)
Lets give our scraper variable as bookInfo and HTTP method as get and also our template location.
 Creating the Query
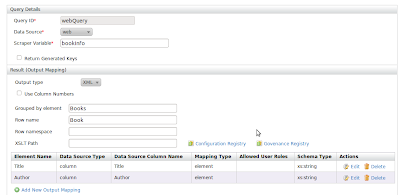
Creating the QueryClick on next to add a query. Give a queryId, scraper variable as webQuery and bookInfo.
To populate the data properly we need to give the group by element and row-name. This is to tell the web service how our result format should be. We also need to give output mapping to arrange our extracted data.
Query information.
- QueryId – webQuery
- Data Source – web
- Scraper Variable-bookInfo
- Grouped by element – Books
- Row name – Book
output mappings
- Element – Title
- Element – Author
Click on Next to add operation and select the query name and give a name to our operation.
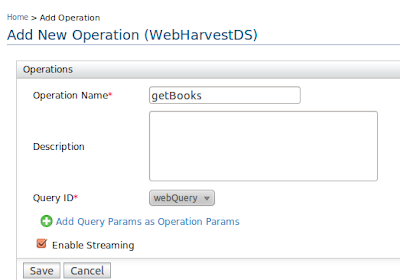
Click on finish to finish creating the data service. Go to webservices list and you can see our webservice is successfully deployed.

You can invoke the service using the try-it tool.
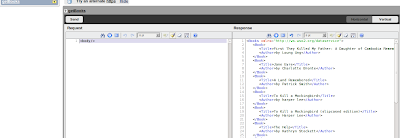 You can also invoke the data service using a rest call by simply typing http://localhost:9763/services/WebScraping/getBooks/ on ur browser.
You can also invoke the data service using a rest call by simply typing http://localhost:9763/services/WebScraping/getBooks/ on ur browser.
Thank you very much. This is a very helpful article. Adds more detail then what is provided by WSO2. Used this as a template to scrape data from am HTML Select with DSS
ReplyDelete
ReplyDeleteThis is a great post about extracting web data. We all know how crucial data is for a business growth and web scraping is serving this purpose. These days a lots of companies that are providing web scraping services to get data as per your requirement and in your desired format. Loginworks has this expertise. They are very proficient in providing the web scraping services
This comment has been removed by the author.
ReplyDeleteNice article about Web Scraping . I appreciate your time and effort. Web Parsing will help you to get the accurate and quality data in the required format.
ReplyDelete토토먹튀
ReplyDeleteDownload Porn Sites
ReplyDeletebuy telegram members We provide all the Telegram services (increase real & fake members - views posts)
ReplyDeleteEvery once inside a though we pick out blogs that we study. Listed below are the most recent internet sites that and for further information please click 먹튀.
ReplyDeletehepsibahis Hepsibahis güncel web sitesine buradan direk giriş yap. Youwin adı ile bilinen Türkiye ve Kıbrıs üzerinden canlı bahis ve casino slot oyun hizmeti veren siteye erişim sağlayın. Hepsi bahis firması için yeni giriş adresi sadece burada.
ReplyDeleteless than one dollar web hosting Domain hosting can be hit and miss when it comes to finding it cheap. Don’t get me wrong there are cheap web hosting options, but how about “super cheap and affordable” web hosting. Less than a dollar is “truly” affordable web hosting and this is a chance to get access to web hosting that is consistent and reliable when it comes to affordable web hosting.
ReplyDeleteBUY SPOTIFY PLAYS REAL PLAYS TO BOOST YOUR MUSIC.
ReplyDeleteWe will promote your tracks and give you very good promotion Buy spotify plays
Share Market News OIBNews is India's leading network by NDTV and CNN contributors. It has been serving the best out of the mess from World and India.
ReplyDeletebaanpolball บ้านผลบอล (baanpolball) อัพเดทตลอด 24 ชั่วโมง ราคาบอลวันนี้ วิเคราะห์บอลแม่น ฟรีๆ ทุกคู่ 100% ทีเด็ดบอลวันนี้ 4 คู่ ราคาบอลไหล แบบเรียลไทม์
ReplyDeletefastest most effective weight loss pill Authentic Option LLC offers collection of natural herbal products for skincare, hair care, and weight loss. We specialize in thermal weight loss, electrostimulation for muscle toning, cellulite removal, under-eye bags treatment and skincare products. We have an amazing range of beard growing products.
ReplyDeleteChicago bike shop
ReplyDeleteChicago bike stores
Kids bikes in chicago
Giant road bikes
Cannonade bikes
Specialized bikes
Facebook Video Downloader
ReplyDeletesagame
ReplyDeletedankwoods,
ReplyDeletefake dankwoods,
ReplyDeletecanim sohbet Android Dear ChatCanım chat is growing day by day with the android chat service it has given to you and serves you, dear chat lovers, free of charge. You can connect and chat online at any time of the day with your smart devices on our chat site. Anonymous chat is a free chat site that allows you to chat randomly and does not charge any fee or money from our valued chat users.
Casinos Now Compare the best legit online casinos that pay real money including the best crypto casinos, best mobile casinos and the best online casinos in 2021
ReplyDeletevirtual reality in education
ReplyDeleteCommercial property management
ReplyDeletebuy dank vapes
ReplyDeletemotherhood CO.MOM is a fun new online magazine and social network community created by moms for moms. Read interesting articles, get advice from our agony aunt, aunt\y anne, learn how to earn an income online with our guru debbie or you can even seek medical advice from our resident physician dr samantha and relax while checking out the latest horoscopes from our trained mystic. Theres even a thriving forum community where moms of the world can get together and enjoy good conversation along with lots of other fun ways to kill some time with a cuppa when taking a break from being super mom at co.mom.
ReplyDeleteWeb Syndication
ReplyDeleteGetvirtual office in dubai- Establish Your Company's presence in the Most Prestigious Business Address and Get a new height to your business.
ReplyDelete